
tl;dr:
- Deep neural networks are forcing us to rethink what it means to understand what a neuron is doing
- Does it make sense to talk about a neuron representing a single feature instead of a confluence of features (a la Kording)? Is understanding the way a neuron responds in one context good enough?
- If a neural response is correlated with something in the environment, does it represent it?
- There is a difference in understanding encoding versus decoding versus mechanistic computations
- Picking up from an argument on twitter
- I like the word manticore
What if I told you that the picture above – a mythical creature called a manticore – had a representation of a human in it? You might nod your head and say yes, that has some part of a human represented in it. Now what if I told you it had a representation of a lion? Well you might hem and haw a bit more, not sure if you’d ever seen a grey lion before, or even a lion with a body that looked quite like that, but yes, you’d tentatively say. You can see a kind of representative lion in there.
Now I go further. That is also a picture that also represents a giraffe. Not at all, you might say. But I’d press – it has four legs. It has a long body. A tail, just like a giraffe. There is some information there about what a giraffe looks like. You’d like at me funny and shrug your shoulders and say sure, why not. And then I’d go back to the beginning and say, you know what, this whole conversation is idiotic. It’s not representative of a human or a lion or a giraffe. It’s a picture of a manticore for god’s sake. And we all know that!
Let’s chat about the manticore theory of neuroscience.
One of the big efforts in neuroscience – and now in deep neural networks – has been to identify the manticores. We want to know why this neuron is responding – is it responding to a dark spot, a moving grating, an odor, a sense of touch, what? In other words, what information is represented in the neurons responses? And in deep networks we want to understand what is going on at each stage of the network so we can understand how to build them better. But because of the precise mathematical nature of the networks, we can understand every nook and cranny of them a bit better. This more precise understanding of artificial network responses seems to be leading to a split between neuroscientists and those who work with Deep Networks on how to think about what neurons are representing.
This all started with the Age of Hubel and Wiesel: they found that they could get visual neurons to fire by placing precisely located circles and lines in front of an animal. This neuron responded to a dark circle here. That neuron responded to a bright line there. These neurons are representing the visual world through a series of dots and dashes.
And you can continue up the neural hierarchy and the complexity of stimuli you present to animals. Textures, toilet brushes, faces, things like this. Certain neurons look like they code for one thing or another.
But neurons aren’t actually so simple. Yes, this neuron may respond to any edge it sees on an object but it will also respond differently if the animal is running. So, maybe it represents running? And it also responds differently if there is sound. So, it represents edges and running and sound? Or it represents edges differently when there is sound?
This is what those who work with artificial neural networks appreciate more fully than us neuroscientists. Neurons are complex machines that respond to all sorts of things at the same time. We are like the blind men and the elephant, desperately trying to grasp at what this complex beast of responses really us. But there is also a key difference here. The blind men come to different conclusions about the whole animal after sampling just a little bit of the animal and that is not super useful. Neuroscientists have the advantage that they may not care about every nook and cranny of the animal’s response – it is useful enough to explain what the neuron responds to on average, or in this particular context.
Even still, it can be hard to understand precisely what a neuron, artificial or otherwise, is representing to other neurons. And the statement itself – representation – can mean some fundamentally different things.
How can we know what a neuron – or collection of neurons are representing? One method that has been used has been to present a bunch of different stimuli to a network and ask what it responds to. Does it respond to faces and not cars in one layer? Maybe motion and not still images in another?
You can get even more careful measurements by asking about a precise mathematical quantity, mutual information, that quantifies how much of a relationship there is between these features and neural responses.
But there are problems here. Consider the (possibly apocryphal) story about a network that was trained to detect the difference between Russian and American tanks. It worked fantastically – but it turned out that it was exploiting the fact that one set of pictures were taken in the sunlight and another set was taken when it was cloudy. What, then, was the network representing? Russian and American tanks? Light and dark? More complex statistical properties relating to the coordination of light-dark-light-dark that combines both differences in tanks and differences in light intensities, a feature so alien that we would not even have a name to describe it?
At one level, it clearly had representations of Russian tanks and American tanks – in the world it had experienced. In the outside world, if it was shown a picture of a bright blue sky it may exclaim, “ah, [COUNTRY’S] beautiful tank!” But we would map it on to a bright sunny day. What something is representing only makes sense in the context of a particular set of experiences. Anything else is meaningless.
Similarly, what something is representing only makes sense in the context of what it can report. Understanding this context has allowed neuroscience to make strides in understanding what the nervous system is doing: natural stimuli (trees and nature and textures instead of random white noise) have given us a more intimate knowledge of how the retina functions and the V2 portion of visual cortex.
We could also consider a set of neurons confronted with a ball being tossed up and down and told to respond with where it was. If you queried the network to ask whether it was using the speed of the ball to make this decision you would find that there was information about the speed! But why? Is it because it is computing the flow of the object through time? Or is it because the ball moves fastest when it is closed to the hand (when it is thrown up with force, or falls down with gravity) and is slowest when it is high up (as gravity inevitably slows it down and reverses its course)? Yes, you could now read out velocity if you wanted to – in that situation.
There are only two ways to understand what it is representing: in the context of what it is asked to report, and if you understand precisely the mechanistic series of computations that gives rise to the representation – and it maps on to ‘our’ definition.
Now ask yourself a third question: what if the feature were somehow wiped from the network and it did fine at whatever task it was set to? Was it representing the feature before? In one sense, no: the feature was never actually used, it was just some noise in the system that happened to correlate with something we thought was important. In another sense, yes: clearly the representation was there because we could specifically remove that feature! It depends on what you mean by representation and what you want to say about it.
This is the difference in encoding vs decoding. It is important to understand what a neuron is encoding because we do not know the full extent of what could happen to it or where it came from. It is equally important to understand what is decoded from a neuron because this is the only meaningfully-encoded information! In a way, this is the difference between thinking about neurons as passive encoders versus active decoders.
The encoding framework is needed because we don’t know what the neuron is really representing, or how it works in a network. We need to be agnostic to the decoding. However, ultimately what we want is an explanation for what information is decoded from the neuron – what is the meaningful information that it passes to other neurons. But this is really, really hard!
Is it even meaningful to take about a representation otherwise?
Ultimately, if we are to understand how nervous systems are functioning, we need to understand a bit of all of these concepts. But in a time when we can start getting our hands around the shape of the manticore by mathematically probing neural responses, we also need to understand, very carefully, what we mean when we say “this neuron is representing X”. We need to understand that sometimes we want to know everything about how a neuron responds and sometimes we want to understand how it responds in a given context. Understanding the manifold of possible responses for a neuron, on the other hand, may make things too complex for our human minds to get a handle on. The very particulars of neural responses are what give us the adversarial examples in artificial networks that seem so wrong. Perhaps what we really want is to not understand the peaks and troughs of the neural manifold, but some piecewise approximations that are wrong but understandable and close enough.
Other ideas
- Highly correlated objects will provide information about each other. May not show information in different testing conditions
- What is being computed in high-D space?
- If we have some correlate of a feature, does it matter if it is not used?
- What we say we want when we look for representations is intent or causality
- This is a different concept than “mental representation“
- Representation at a neuron level or network level? What if one is decodable and one is not?
- We think of neurons as passive encoders or simple decoders, but why not think of them as acting on their environment in the same way as any other cell/organism? What difference is there really?
- Closed loop vs static encoders
- ICA gives you oriented gabors etc. So: is the representation of edges or is the representation of the independent components of a scene?


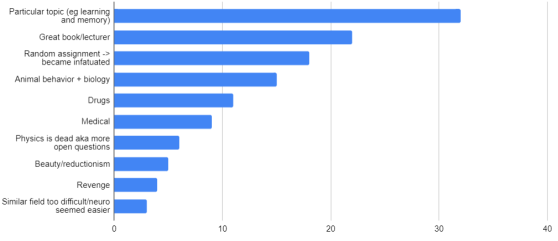

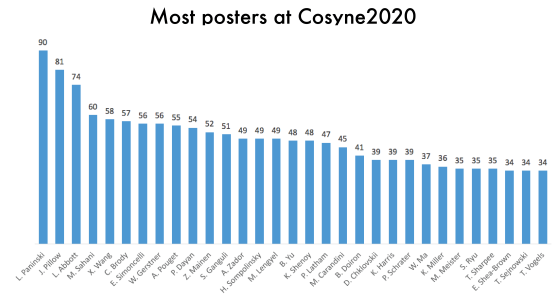
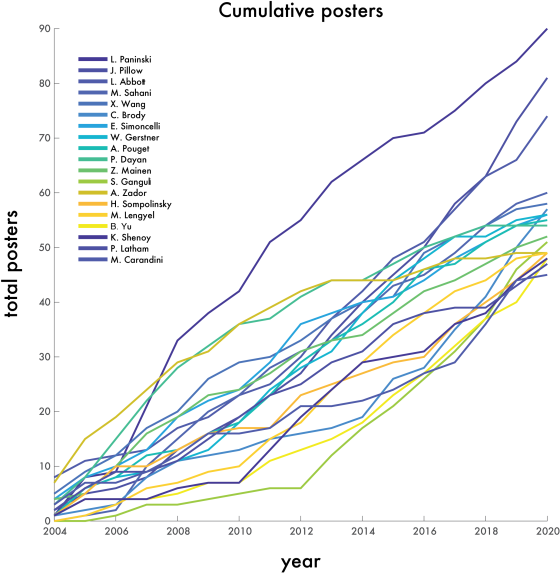



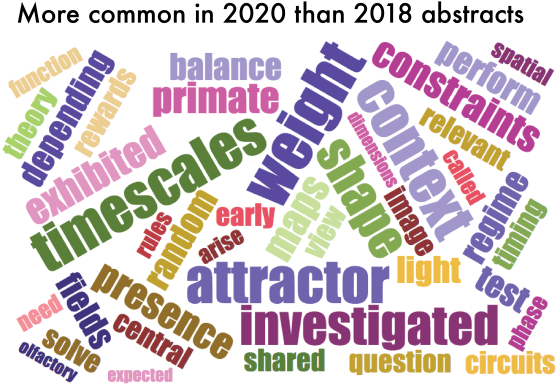
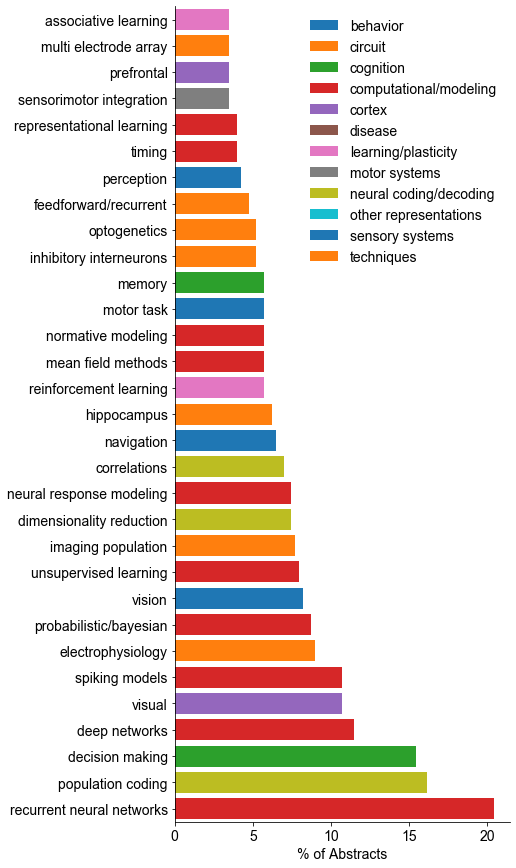
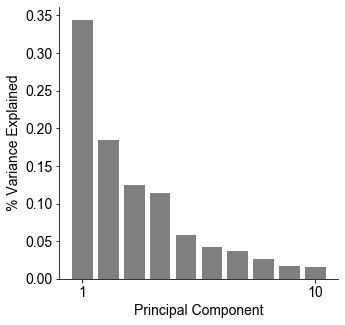

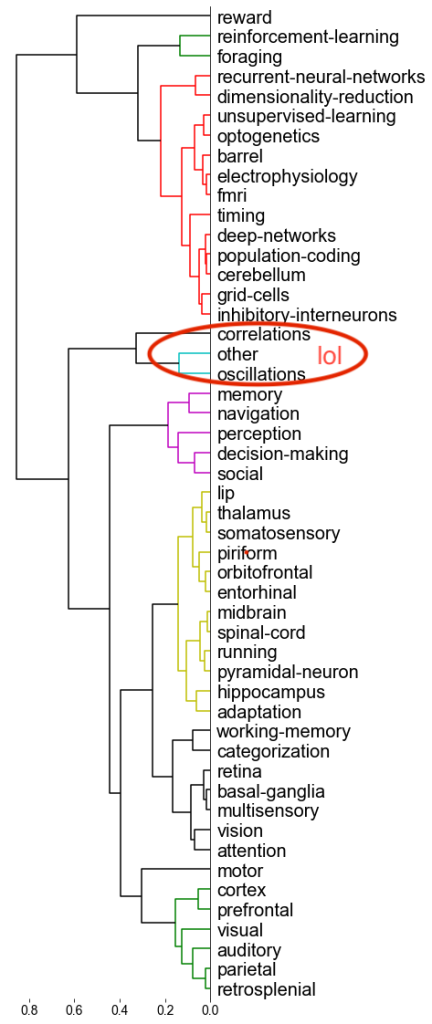
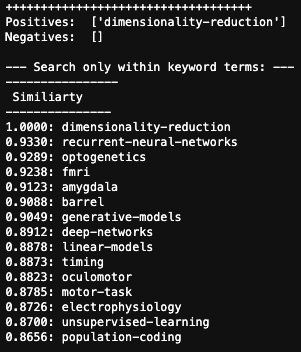

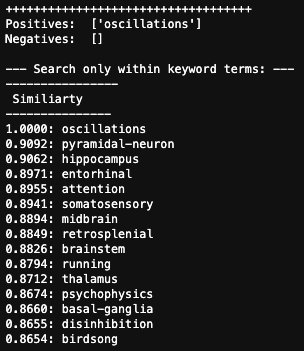



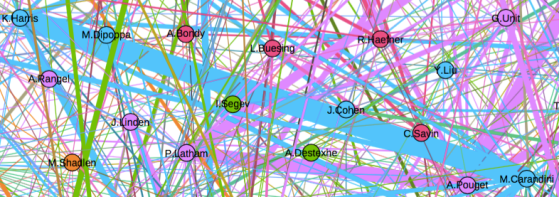


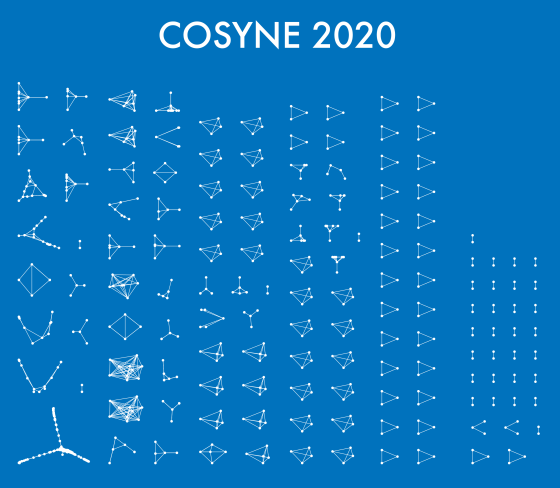



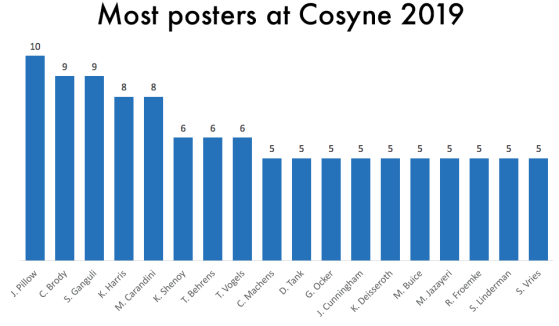
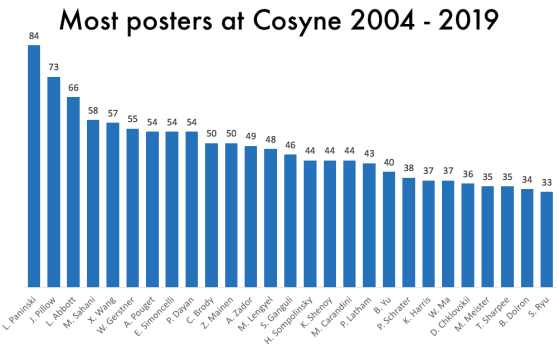

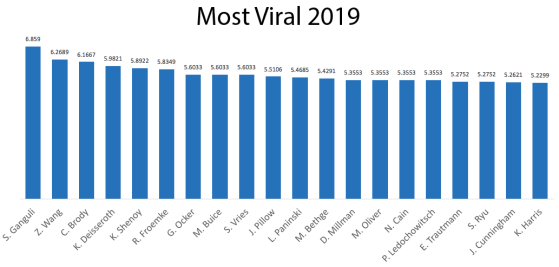



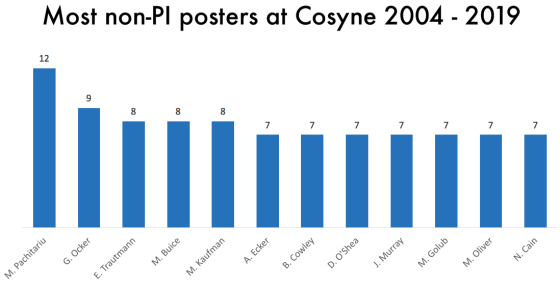









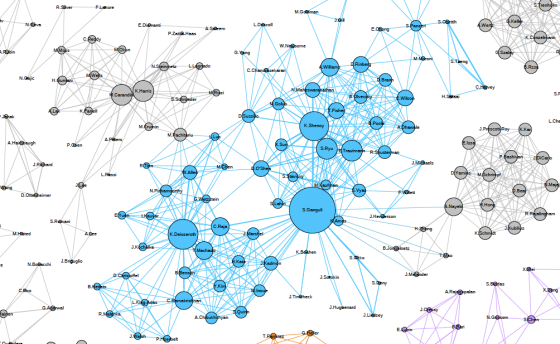

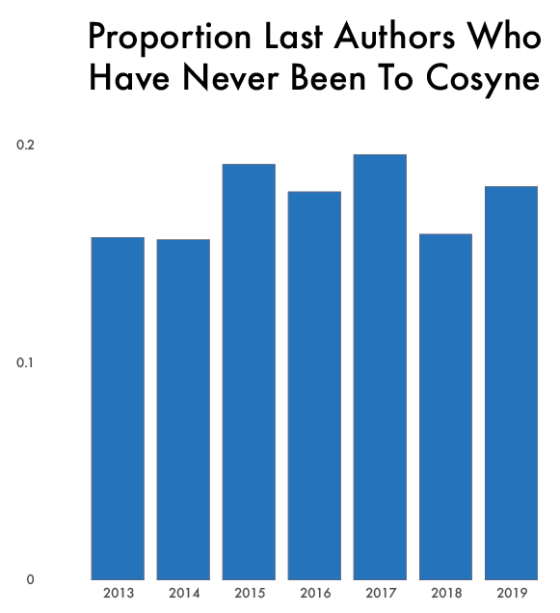
 One thing that is changing is the proportion of authors who belong to the largest subgraphs of the network – that is, who is connected to the “in-group” of Cosyne. And the in-group is larger than ever before:
One thing that is changing is the proportion of authors who belong to the largest subgraphs of the network – that is, who is connected to the “in-group” of Cosyne. And the in-group is larger than ever before:


